Employment and poverty in rural areas of Armenia: Machine learning driven analysis
Employment and poverty in rural areas of Armenia: Machine learning driven analysis
Date:
May 26, 2017
By Erik Hambardzumyan
CRRC-Armenia Junior Fellow
The aim of this blog post is to give insights with regard to employment dynamics in Armenia. Most of the analysis is based on Caucasus Barometer 2015 survey data, World Bank data and official employment statistics report of National Statistical Service of Armenia (NSS). The analysis consists of two parts: the first one is the descriptive analysis of the employment sectors dynamics; the second part is machine learning techniques analysis[1].
Descriptive analysis of the employment sectors dynamics
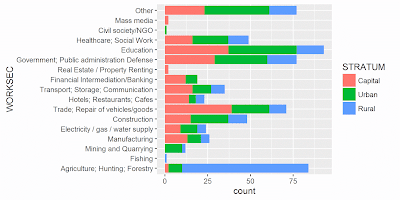
To get an overview of overall employment dynamics, it would be worth examining the employment sectors for the three strata: rural, urban and capital using Caucasus Barometer 2015 data. As the figure 1 shows, the majority in the rural areas is engaged in agriculture. As for the capital, most of the people are engaged in trade, repair of vehicles or goods, while in urban areas the majority is in the education. Agriculture appears to be the major source of employment in rural areas. Given the fact that rural population comprises 37.3% of the population[2] it is worth examining the agriculture sector dynamics using productivity as the key metric. One way to compute the productivity in the context of the problem is to measure the value-added generated by a person engaged in the sector.
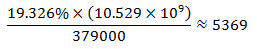
As for services, value-added (as % of GDP) was 51.892%[6], given 523000 people are involved in the sector.
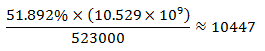
As we can see service sector is almost twice as productive as agriculture sector.
The machine learning part
It is crucial to define the ‘High’ and ‘Low’ incomes in the context of the problem; the income over 400 USD per capita is defined as ‘High’ income and under 400 USD per capita – ‘Low’ income. Furthermore, the prior examinations of the dataset led to the following a priori decision rules with regard to person’s income. If a person has an advanced computer knowledge, is male and if he works in the banking sector as a manager, he will have high probability of being in ‘High’ income class. As for the ‘Low’ income, if one has no basic computer knowledge, is female and works in education sector having elementary occupation he has high probability to be in the ‘Low’ income class.
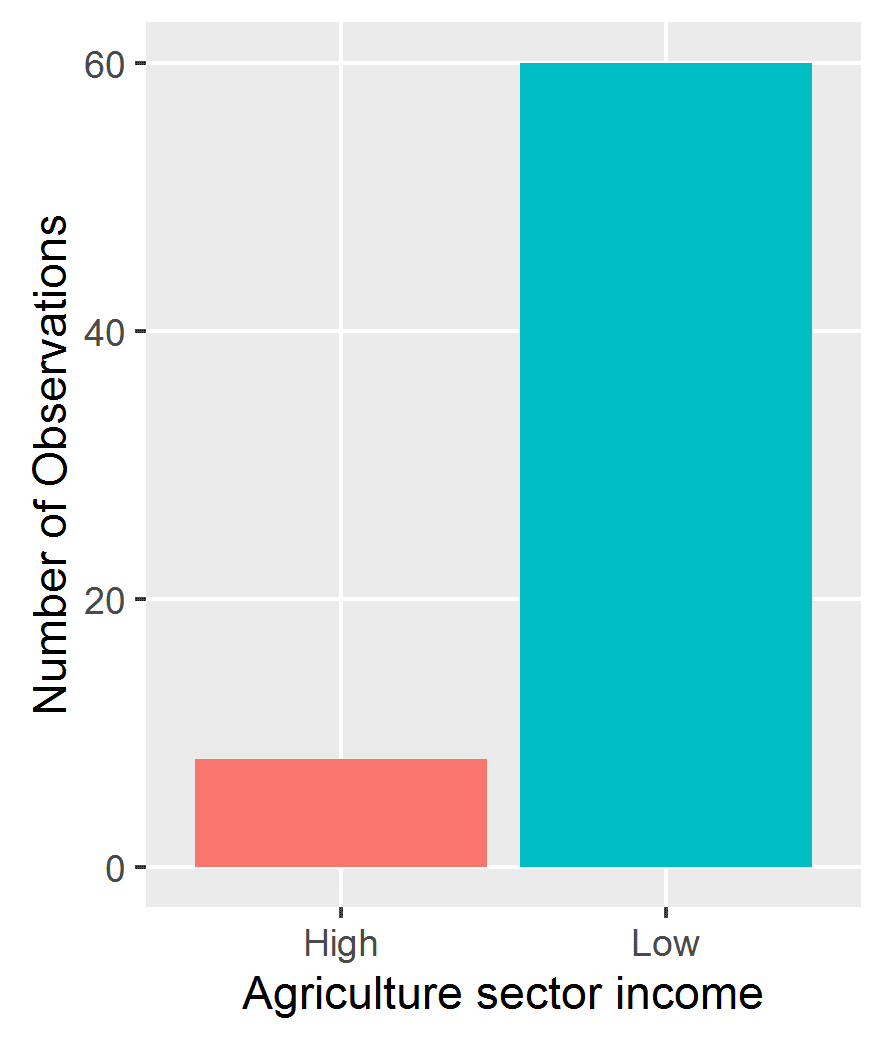 |
| Figure 2 |
The figure 2 reveals the distribution of respondents’ income engaged in agriculture, hunting, forestry. It shows that the majority (89% of all engaged) are low income class people.
Having this in mind let us compare with the evidence gained by the decision tree algorithm (figure 3). Note that if one’s employment sector (WORKSEC) is not mining/quarrying, electricity, gas, water supply etc. than it is agriculture, hunting, forestry, manufacturing, education, and healthcare. It is essential to consider that model’s predictive accuracy is 78% which means out of 100 instances it correctly predicts 78 of them.
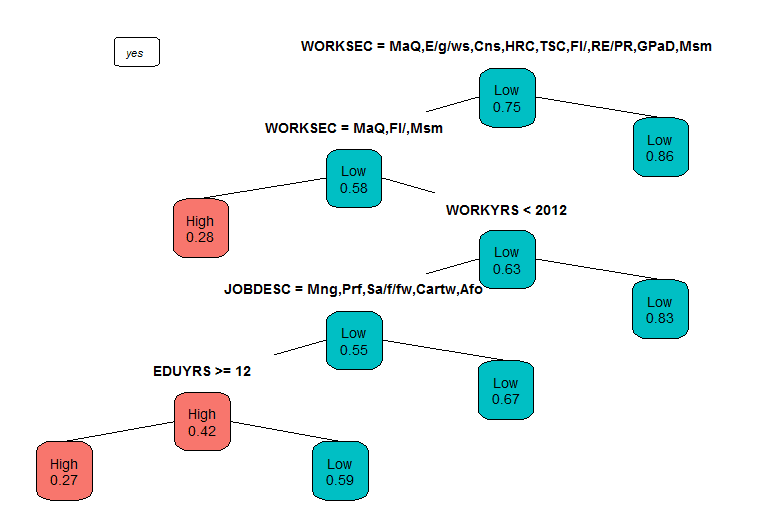 |
| Figure 3 |
If respondent’s work sector is not mining/quarrying, electricity, gas, water supply etc. we turn to the left and get the 86% probability of that person being the part of low income class; in the same fashion if that person belongs to either mining and quarrying, financial intermediation/banking, mass media work sectors then the probability of that person being in the ‘High’ class is 28%. Hence, the highest probability of one being in the ‘High’ income class (100%-55%=45%) is when the person belongs to either mining/quarrying, financial intermediation/banking, mass media work sectors or when his or her employment duration starts earlier than 2012. Most of the abstract rules that the model is suggesting, are quite intuitive and close to our prior determinations. The model hints that the driving factor of one’s income in Armenia is employment.
Conclusion
Based on the findings most of the people in the rural areas are involved in agriculture which is a very low productivity sector; almost twice less productive than services sector. According to the decision tree model people employed in agriculture, hunting, forestry, manufacturing, education, and healthcare are poor. Moreover, 86 out of 100 people of either sector can be identified as low income people.
[1] The workings have been fully done using R statistical software; the full information about the workings (figures, decision trees) with code can be found here
[2] http://data.worldbank.org/indicator/SP.URB.TOTL.IN.ZS?locations=AM
[3] http://data.worldbank.org/indicator/NV.AGR.TOTL.ZS?locations=AM
[4] http://data.worldbank.org/indicator/NY.GDP.MKTP.CD?locations=AM
[5] http://www.armstat.am/file/article/9.trud_2016_4.1.pdf
[6] http://data.worldbank.org/indicator/NV.SRV.TETC.ZS?locations=AM
The content of this blog is the sole responsibility of the author and does not necessarily reflect the views of CRRC-Armenia.
Category
Blog